
The bulk_extractor command we run in the terminal
The bulk_extractor command we run in the terminal
Social security numbers. Medical records. Academic transcripts. Email addresses. GPS coordinates. These may be left behind as traces of an individual’s or organization’s digital life. In the Special Collections Research Center, we acquire born digital materials, which refer to files originating in a computer environment. They often take the form of floppy disks, CDs, flash drives, cloud storage transfers, and external hard drives. Examples of collections with these materials include the Alexander Isley Papers and Humane Society of the United States Records. We don’t expect donors to give us files containing private or personally identifiable information (PII). However, given the large volume of files they create, PII can remain on the storage media we receive. As archivists, our mission is to provide access, but we also want to protect donor privacy and comply with laws, such as FERPA and HIPAA, state statutes, and university policies.
To help us identify PII and confidential materials during processing, we use bulk_extractor. This is a free, open-source tool that was created by Simson L. Garfinkel. We run in a terminal (pictured above). Bulk_extractor uses algorithms to search for PII, including: social security, credit card, telephone, and phone numbers; birth dates; email and IP addresses; and Google search history. We can also provide bulk_extractor with our own list of terms to look for. It was originally designed as a digital forensics tool and is commonly used in cybercrime investigations. Thus, our custom term list includes words specific to the university, like “Drop Add” and “SAT.”
bulk_extractor can even find PII hidden in files! For example, a JPEG image can be opened in a hex editor, which shows the raw binary data that makes up the JPEG, and edited without altering its visible representation. Shown below is a JPEG open in a photo viewer and the same JPEG open in a hex editor. If you look closely, you’ll notice the SCRC phone number, (919) 515-2273, hidden in the decoded text of the binary data.
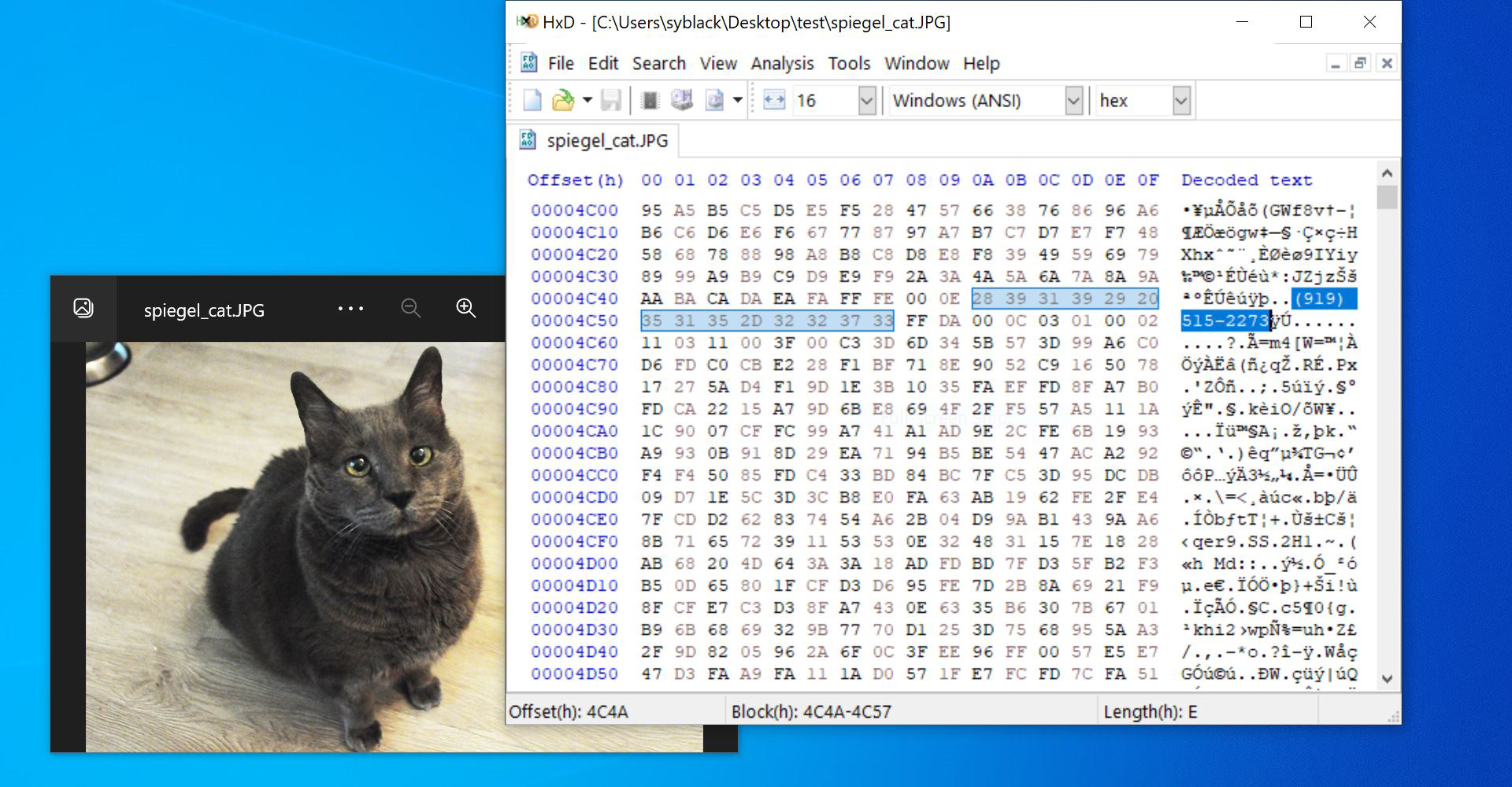
Yet what happens when the JPEG is a picture taken of PII, such as a cell phone or flatbed scanner photo of a passport or bank statement? bulk_extractor won’t “see” this kind of PII. In this scenario, we’d need to use a tool that uses optical character recognition to generate text from image files first, then run bulk_extractor on that text.
Another one of bulk_extractor’s limitations is that it only searches through the contents of files. It cannot detect PII in file names. In response, we created a Python script that parses file and directory names for keywords we provide. For example, given the keyword “1040,” the script can identify a file called f1040new.pdf and save the results in a report.
bulk_extractor is a powerful tool that helps us identify what to exclude before moving files to preservation storage and making them publicly available. Technology automates much—but not all—of the privacy review. Human intervention is still necessary. bulk_extractor only looks for patterns, resulting in false positives. Also, information can be private, depending on the context and parties involved. Consequently, we continue to combine manual review with the use of efficient digital tools. It’s our ethical obligation to minimize the risk of exposing sensitive information.
If you have any questions or are interested in viewing Special Collections materials, please contact us at library_specialcollections@ncsu.edu or submit a request online. The Special Collections Research Center is open by appointment only. Appointments are available Monday–Friday, 9am–6pm and Saturday, 1pm–5pm. Requests for a Saturday appointment must be received no later than Tuesday of the same week.
Opens in your default email client
URL copied to clipboard.